关于解决类似「大众点评」字体反爬的方法
关于解决类似「大众点评」字体反爬的方法
反爬虫的常规方式通常包括: IP限流, UA 限制, Cookie 限制等。解决办法也比较常规,通过在 Header 中不断更换伪造的信息或者使用代理IP的方式来隐藏自己的爬虫。
不过机智的反爬虫工程师从来没有停止思考,想出了通过字体文件来隐藏数据;
大众点评中包含很多商家信息,是一个巨大的数据中心,对于电话和地址这些信息,需要进行反爬;正常用户能看到的信息,通过控制台分析和HTML源码分析得到的却是乱码。
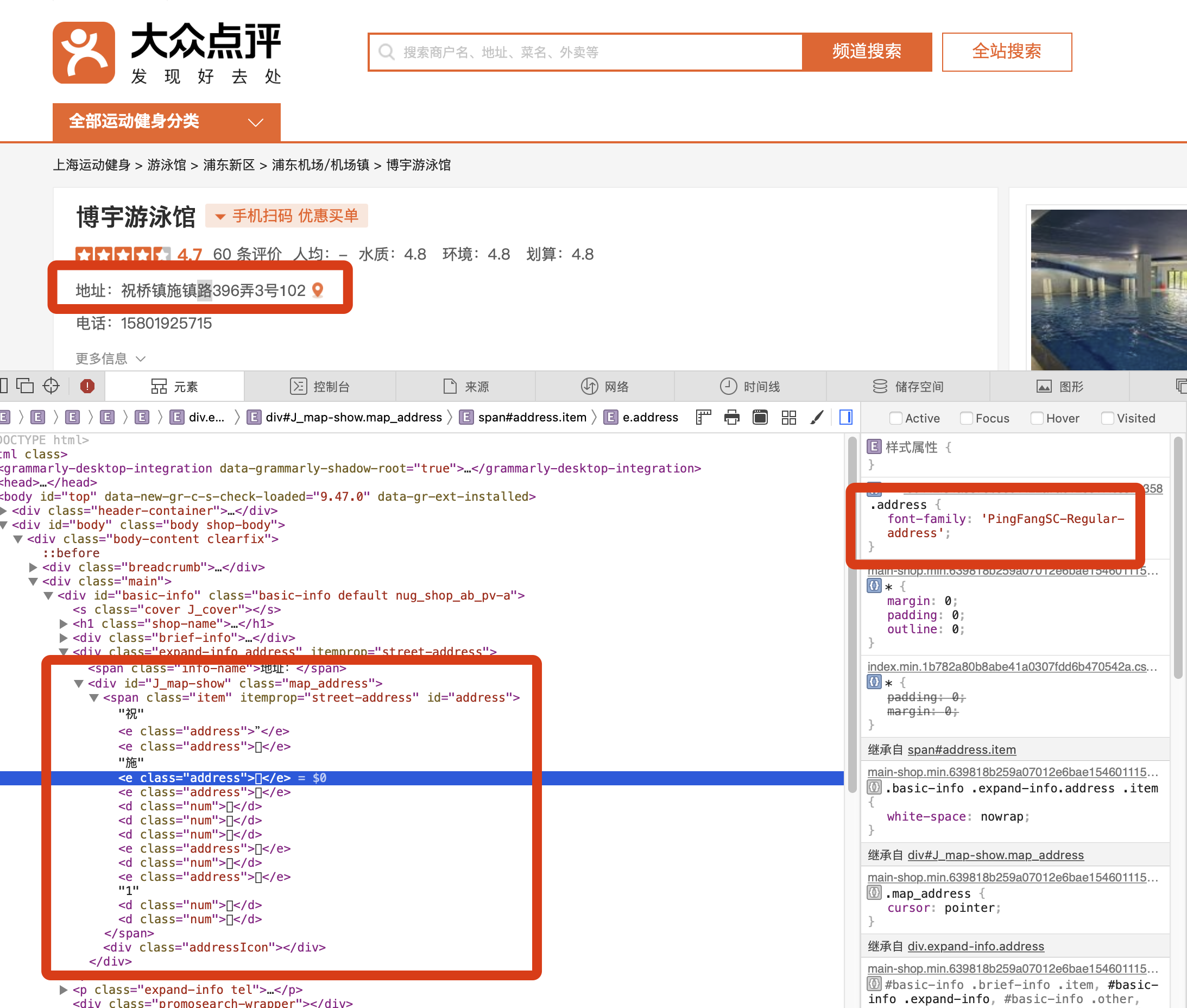
很显然,爬出这样的数据是没有意义的,还是需要继续深入,找到解决办法。
抓耳挠腮……
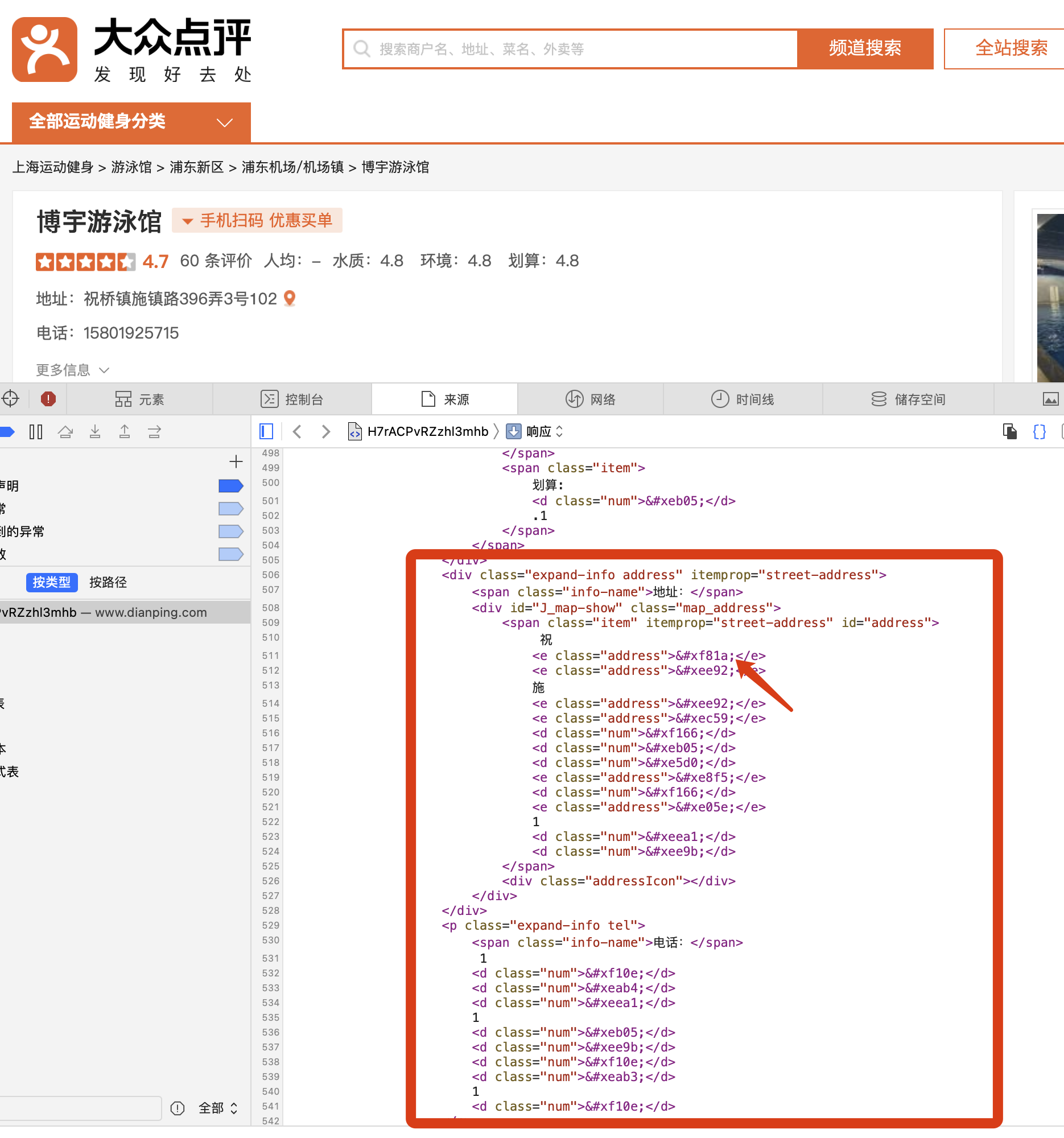
仔细分析发现,它是用字体文件来映射了具体的文字内容,利用CSS样式表来渲染到页面上,单单分析HTML是没有用的,还需要分析字体和样式表文件。
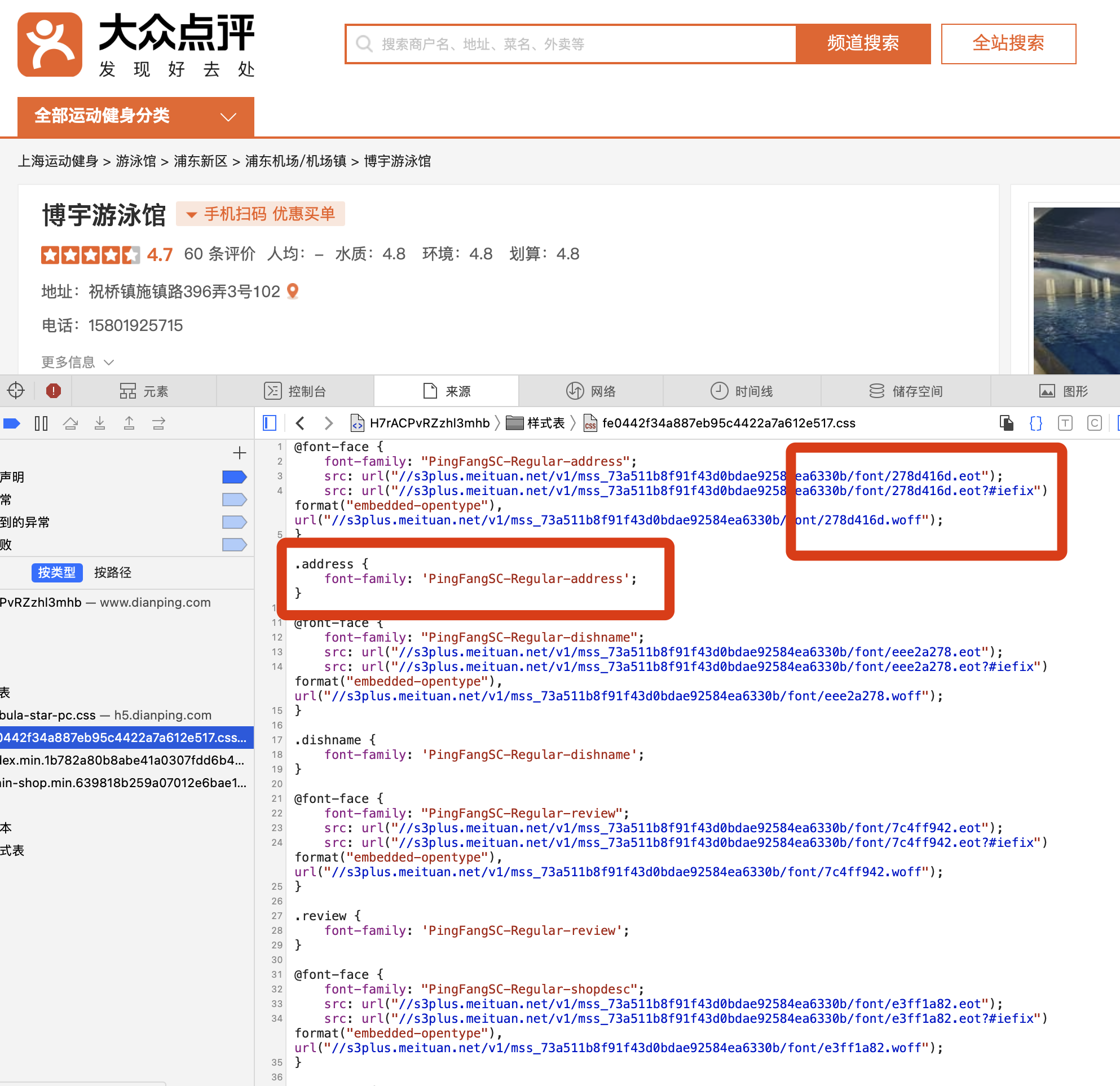
下图是通过字体文件打开的 woff 文件,可以看到每个字都对应了一个编码,通过分析,这个编码就对应着页面上的html乱码。

将其中的编码和文字做一个映射,再生成一个python可读的字典来完成替换。
于是,接下来就是导出文字和编码的映射关系即可。
简单来说,就是把字体文件中每个字上面对应的编码和字体做一个映射,这听起来很简单,但是没有什么好的办法来完成,只能手动操作。
虽然没什么技术难度,但是纯粹是体力活,而且伤眼睛,时间长了为数不多的毛发也会脱落。
感谢大神提供的工具 fontTools ,它可以读取字体文件并识别出文字上面的编码,于是我想到一个骚操作,通过图片转文字,把里面的文字都识别出来,然后通过 fontTools 工具来读取字体文件中的编码,只要2者顺序是一样的,就可以按顺序读取,并添加到字典中。
from fontTools.ttLib import TTFont
import json
text="""1234567890店中美家
馆小车大市公酒行国品发电金心业商
司超生装园场食有新限天面工服海华
水房饰城乐汽香部利子老艺花专东肉
菜学福饭人百餐茶务通味所山区门药
""".replace('\n','')
fonts = { 'address': '278d416d.woff', 'num': '278d416d.woff'}
for n, t in fonts.items():
font = TTFont(t) # 打开本地的ttf文件
textOrder = font.getGlyphOrder()[2:]
dict = {}
for i in range(0, len(textOrder)):
dict[textOrder[i][3:]] = text[i]
fonts[n] = dict
with open('text.json', 'w') as f:
f.write(json.dumps(fonts, ensure_ascii = False))
通过这种方式,可以得到一个 text.json 文件,里面包含了编码和文字的对应,后面就可以进行内容的转换了。
反爬工程师们还会定期更新这个字体文件来提醒我们爬虫要更新了。不过还好,只是改变了文字上面的编码,文字的数量和顺序都没有变化,只要重新跑一下上面的脚本,就可以更新了。